由于JVM的跨平台设计,Java的指令是在堆栈上设计的。
下图为一个类的class从加载到为其分配内存的示意图,后续主要一一介绍各部分的具体work以及它们的组成
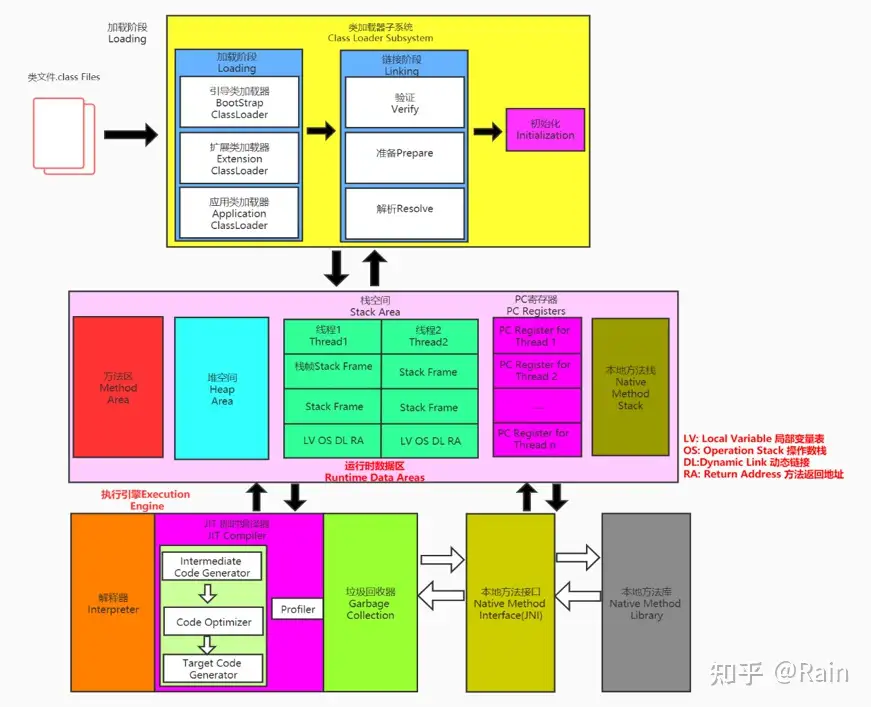
类装载子系统(Class Load SubSystem)
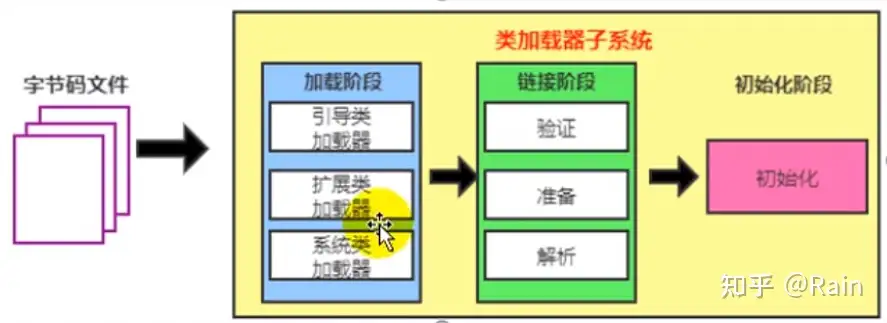
Loading(加载阶段)
生成一个java.lang.Class对象,作为方法区域中Class的各种数据的访问点,类加载阶段主要通过类加载器(ClassLoader)进行加载
其中类加载器又包含三个类型:
BootStrap ClassLoader
- C/C++编写
- 没有父加载器
- 加载 Extension ClassLoader 和 Application ClassLoader
Extension ClassLoader
- java编写
- 派生于ClassLoader.Class
App ClassLoader
- java编写
- 派生于ClassLoader.Class
- 父辈:Extension ClassLoader
- 默认的类加载器
双亲委派机制
所谓双亲委派机制就是类对于加载器的选择:获取父辈的ClassLoader,如果它的父辈还有父辈,就递归继续往上找一直到最高级,如果父系加载器可以运行就return,否则就自己加载。双亲委派机制的优势:避免类被重复加载,避免核心API被篡改。
沙箱机制
沙箱机制是将java代码限制在虚拟机(JVM)的特定运行范围内,并严格限制代码对本地系统资源的访问。 这些措施可以确保代码的有效隔离,防止对本地系统的破坏。
Linking(链接阶段)
Verify->Prepare->Resolve。确保class文件字节流中的信息符合虚拟机规范,主要体现在:文件格式、元数据、字节码、符号引用
Prepare
为类变量分配内存并初始赋值0,这里不包含用final修饰的static,因为final修饰的在编译的时候就会分配内存,这里只是显式初始化(即将值附上)
Resolve
将常量池内的符号引用转换为直接引用
Initilization(初始化阶段)
即执行类构造器方法<clinit>()的过程
运行时数据区(Run-Time Data Areas)
PC寄存器(Programe Counter Register)

定义
Java虚拟机可以同时支持多个线程的执行。每个Java虚拟机线程都有自己的PC Register。 在任何时候,每个Java虚拟机线程都在执行单个方法的代码,即该线程的当前方法。如果该方法不是本地的,PC Register包含当前正在执行的Java虚拟机指令的地址。 如果当前线程执行的方法是本地的,那么Java虚拟机的PC Register的值是未定义的。 Java虚拟机的PC Register足够宽,可以容纳特定平台上的一个returnAddress或一个本机指针。
作用
当一个线程被执行到一半的时候,Java虚拟机又执行其他的线程,再回到该线程时可以告诉Java虚拟机从哪个指令开始继续执行。
Java虚拟机栈(Java Virtual Machine Stack)
Java虚拟机栈是由栈的数据结构实现的,它的优势在于指令集小,操作简单(FILO),可以在各种平台上轻松实现。缺点是效率不如寄存器高。
当线程中计算需要用到超出Java虚拟机规定的栈大小时,会抛出StackOverFlowError。当Java虚拟机没有内存再为线程创建一个栈时,会抛出OutOfMemoryError。
ps:可通过-Xss来设置线程的最大栈空间。
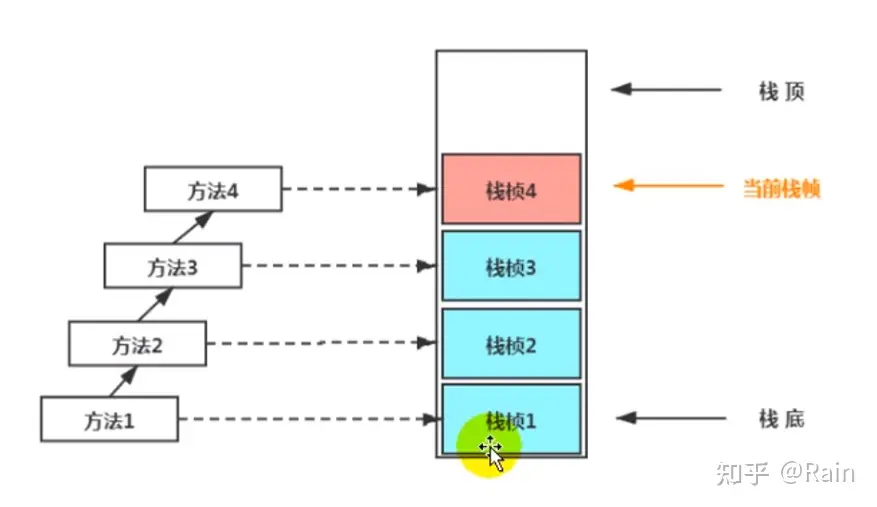
基本单位:栈帧
Java栈主要用于存储栈帧(Stack Frame),而栈帧中则负责存储局部变量表、操作数栈、动态链接和方法返回值等信息。每个栈帧代表一个线程中的一个方法,当方法被执行时,栈帧入栈,方法执行完后,栈帧出栈,当前栈的最顶上的栈帧代表这个线程的当前方法。
栈帧内又包含(局部变量表、操作数栈、动态链接、方法返回地址、一些其他信息)
局部变量表(Local Variables)
基本单位:Slot
每一个栈帧都包含一个变量数组,称为局部变量。栈帧的局部变量数组的长度在编译时确定,并在类或接口的二进制表示形式中提供,以及与帧相关的方法的代码。单个局部变量可以保存boolean,byte,char,short,int,float, reference,或returnAddress(占一个Slot)。一对局部变量可以保存long或double类型的值(占两个Slot)。
局部变量通过索引来寻址。第一个局部变量的索引为零。当且仅当该整数小于局部变量数组的大小时,该整数被认为是局部变量arra的索引。类型为long或double的值占用两个连续的局部变量。
ps:局部变量表中的变量是重要的GC根节点,只要被局部变量表中直接引用或者间接引用的对象都不会被回收
操作数栈(Operand Stacks)
每一个栈帧都包含一个后进先出(LIFO)堆栈,即操作数堆栈。栈帧的操作数堆栈的最大深度在编译时确定。当包含它的帧被创建时,操作数堆栈是空的。 Java虚拟机提供了将常量或值从局部变量或字段加载到操作数堆栈的指令。其他Java虚拟机指令从操作数堆栈中获取操作数,对它们进行操作,并将结果推回到操作数堆栈中。 操作数堆栈还用于准备传递给方法的参数和接收方法结果。在任何时候,操作数堆栈都有一个关联的深度,其中long或double类型的值为深度贡献两个单位,任何其他类型的值为深度贡献一个单位。
动态链接(Dynamic Linking)
方法的类文件代码引用要调用的方法和要通过符号引用访问的变量。动态链接将这些符号方法引用转换为具体的方法引用,在需要时加载类来解析尚未定义的符号(ClassLoad Process时的reslove环节),将变量访问转换为与这些变量的运行时位置相关的存储结构中的适当偏移量。
方法返回地址(Method Return Address)
方法换回地址用于指向方法结束时要返回的具体地址,对应PC寄存器的下一个指向。
一些其他信息(Method Return Address)
栈帧中还允许携带Java虚拟机实现相关的一些附加信息。例如,对程序调试支持的信息。
本地方法栈(Native Method Stack)
- Java虚拟机栈用于管理Java方法的调用,而本地方法栈用于管理本地方法的调用。
- 本地方法栈也是线程私有的。
- 允许被实现成或者是可动态扩展的内存大小
- 当线程请求分配的栈容量超出栈大小时,会报StackOverFlowError;当一个新线程请求分配一个本地方法栈的时候,但内存不足以分配,则会报OutOfMemoryError。
- 通过C语言实现
- 当某一线程调用一个本地方法时,它就进入了一个全新的不受虚拟机限制的世界。它和虚拟机拥有同样的权限。
- 并不是所有的JVM都有本地方法栈,这里只是HotSpot含。
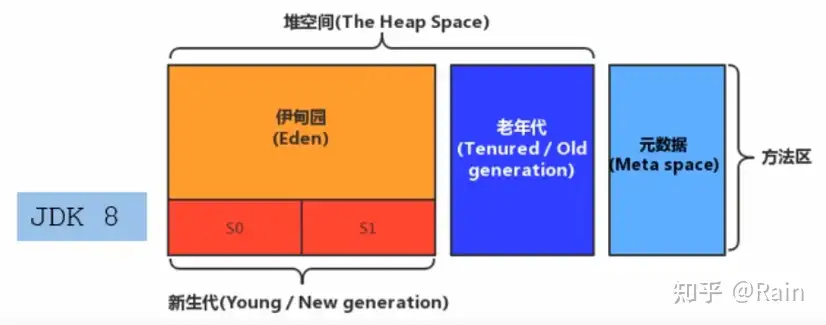
堆 (Heap)
- 一个JVM实例只存在一个堆内存,对也是Java内存管理的核心区域
- Java堆区在JVM启动的时候被创建,堆的大小也被确定。(可以在启动前通过JVM参数进行调节堆内存大小)
- 堆可以在物理上不连续,但在逻辑上连续。(堆和实际物理地址是一一对应的)
- 所有的线程共享Java堆,但也有不共享的(Thread Local Allocation Buffer[TLAB])
- 几乎所有的对象实例和数组都应在运行时分配在堆上。栈帧中不保存,因为栈帧中保存对象实例或数组的引用指向堆空间。
- 方法结束,堆中的对象不会被马上移除,只有GC才会被删除。
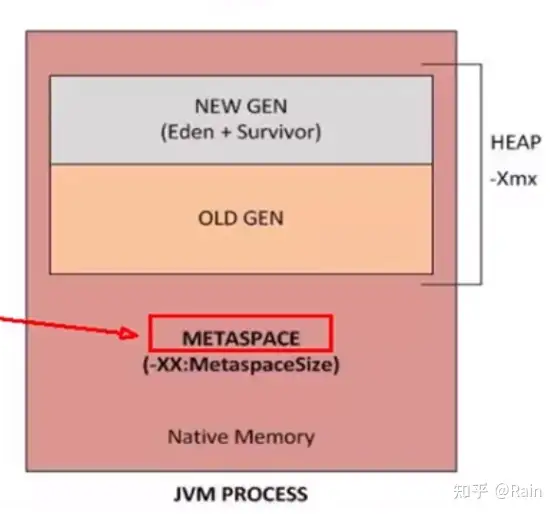
内存细分
现代GC大部分都基于分代收集理论,堆空间细分:
对象分配过程
一个新对象诞生后,首先前往Eden区存放,当Eden区满了之后,JVM会进行一次MinorGC(GC Eden、S0或S1),然后再将新对象存进Eden区,在存入之前,Minor GC之后将Eden区的所有存活对象存入S0或者S1,然后将S0或S1的所有对象copy到S0或S1。当S0或S1的对象age==15时,再进行Minor GC的时候,这些存活在S0或S1的对象会进行一次Promotion(晋升)到Old区,上述说的15也可以通过修改JVM参数进行修改(default是15):-XX:MaxTenuringThreshold=?来进修配置修改。
特殊情况
当一个对象准备进入Eden时,Eden内存不够(已经经过一次Minor GC),该对象将直接进入Old区,或者从Eden转移到S0或者S1时,S0、S1内存不支持该对象存入,也是一样直接晋升Old区。如果一个新对象在Old区也放不下,会进行一次Full GC,还是不行则报OOM。同时,如果发生S0或者S1的中的对象年龄相同且相加内存超过S0或者S1内存的一半,则直接晋升,无需等到MaxTenuringThreshold。
对象分配过程示意图

JVM常用调优工具
- JDK命令行
- Jconsole
- VisualVM
- Jprofiler
- Java Flight Recoder
- GCViewer
- GC Easy
MinorGC MajorGC FullGC对比
MinorGC只发生在Yong区,MajorGC只发生在Old区,FullGC发生在整个堆区和方法区。(MajorGC和FullGC通常情况下是一起混合使用的)
ps:MixedGC 收集整个Yong和部分Old区的垃圾。(只有G1有)
为什么要把Java堆分代?不分代就不能正常工作了?
因为绝大多数的对象(80%左右)都是朝生夕灭的,所以分代后,每次GC只需要GC特定范围的对象,而不是将整个Java堆GC。不分代也是可以的,但是分代是可以优化GC的性能。
对象分配过程:TLAB(Thred Local Allocation Buffer)
前面说了一个新的Obj的诞生首先为其分配的是Heap中的Eden区,这里说的TLAB是指Eden区又划分了一个小区域,这个小区域里负责存储对象,这里面的对象则是分类存储的,具体划分界限则是以线程为边界,一个线程划分Eden中的TLAB中的一个小区域,负责存储该线程中的对象数据。
why need TLAB?
- 堆区是线程共享的,任何线程都可以访问堆中的数据,当对象创建时直接存储在堆中是不安全的(高并发环境下)
- 为了避免多个线程操作同一地址,需要加锁等机制,进而影响了分配的速度。
再看对象分配过程
当new了一个新对象后,JVM首先会将其分配到TLAB区,保证其是线程私有的。如果分配失败,则JVM会尝试使用加锁机制来确保数据操作的原子性。从而直接将数据存在Eden区。
测试堆空间常用的jvm参数
- -XX:+PrintFlagsInitial:查看所有的参数的默认初始值
- -XX:+PrintFlagsFinal:查看所有的参数的最终值
- 具体查看某个参数的指令:jps:查看当前运行中的进程,jinfo -flag SurvivorRatio 进程id
- -Xms:初始堆空间内存(默认为物理内存的1/64)
- -Xmx:最大堆空间内存(默认为物理内存的1/4)
- -Xmn:设置新生代的大(初始值及最大值)
- -XX:NewRatio:配置新生代与老年代在堆结构的占比
- -XX:SurvivorRatio:设置新生代中Eden和S0/S1空间的比例
- -XX:MaxTenuringThreshold:设置新生代垃圾的最大年龄
- -XX:+PrintGCDetails:输出详细的GC处理日志
- 打印GC简要信息:-XX:+PrintGC或者-verbose:gc
- -XX:HandlePromotionFailure:是否设置空间分配担保
方法区(Method Area)


- 方法区与Java堆一样,是各个线程共享的内存区域。
- 方法区在JVM启动的时候被创建,并且它在物理上的地址和堆一样也是可以不连续的。
- 方法区的大小可调整,如果空间不够保存很多的类,则会报OOM:Metaspace
- jdk8以后方法区不保存在运行时数据区,而是直接保存在本地内存。
大小设置
- 可以使用参数-XX:MetaspaceSize=?
- 方法区的大小和它正如它保存的位置一样,它依赖于平台,Windows默认是21M,
- 建议将Metaspace的值调的大一点,因为一旦不够,JVM会进行FullGC,我们希望JVM尽量少的进行FullGC(FullGC耗时高)
如何解决OOM?
- 首先根据相关工具查看内存dump文件进行分析,是内存泄漏还是内存溢出。
- 如果是内存泄漏则可根据工具查看GCroots的引用链,定位到泄露内存的code。
- 如果是内存溢出,则可以适当调整堆栈大小同时也要检查code中是否有过多对象生命周期过长看是否能进行调整。
内存结构
类型信息、常量、静态变量、即时编译器编译的code缓存等。
运行时常量池和常量池
常量池是指class文件编译时解析的包括各种字面量和对类型、域、方法的符号引用。而运行时常量池则是类加载后将常量池的内容放进方法区改名叫做运行时常量池。(其实二者内容相当只是位置、背景更换)
StringTable为什么要调整位置?
因为我们现在的项目中会经常用到String,(jdk7之前)之前StringTable是放在方法区(永久代)的,而永久代的GC只有FullGC时才涉及,而FullGC又只有老年代满了才会触发,所以FullGC触发的概率低,StringTable回收效率也就低。现在将StingTable放进堆中就可以提升它的回收率。

执行引擎(Execution Engine)
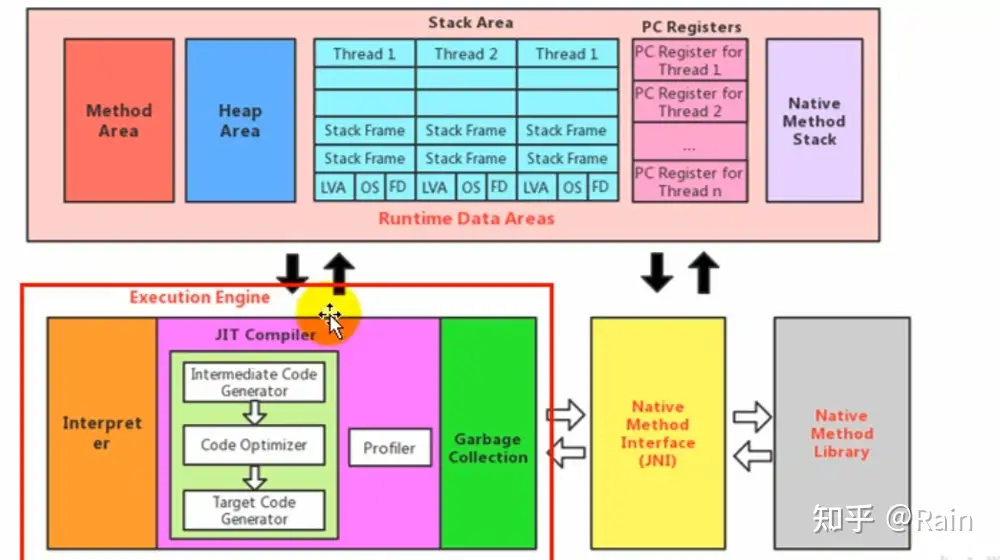
概述
执行引擎是Java虚拟机核心的组成部分之一。
JVM的主要任务是负责装载字节码到其内部,但字节码并不能够直接运行在操作系统之上,因为字节码指令 并非等价于本地机器指令。所以想让一个Java程序运行起来,执行引擎的任务就是将字节码指令解释/编译为对应平台上的本地机器指令才行。
Java代码编译和执行的过程
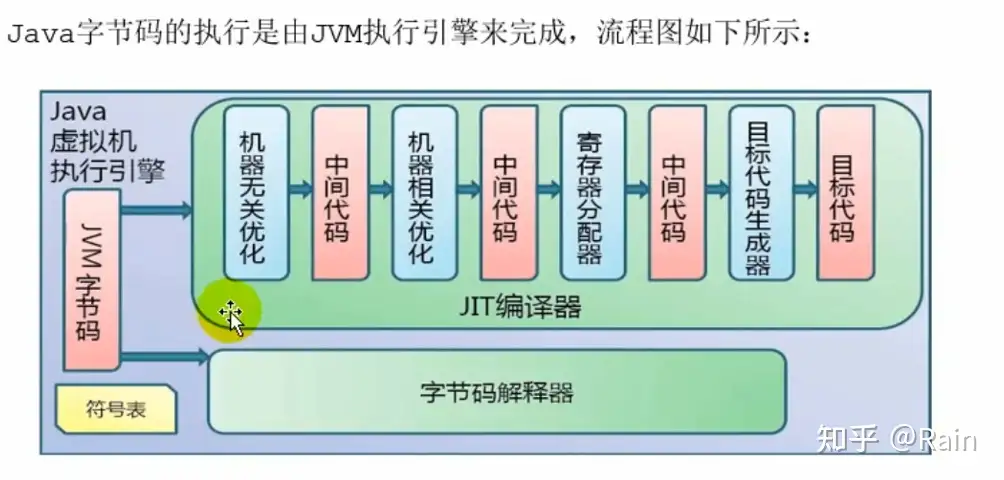
字节码解释器
当虚拟机启动后会根据预定义的规范==对字节码采用逐行解释的方式执行==,将每条字节码翻译成本地机器码。
JIT(Just In Time)编译器
虚拟机直接将源代码直接编译成本地机器相关的机器指令。
HotSpot JVM的执行方式
当虚拟启动时,==解释器可以先发挥作用==,而不用等JIT编译器吧所有代码全部编译完成才执行,这样可以==省去许多不必要的编译时间==。并且随着程序时间的推移,JIT编译器逐渐发挥作用,根据热点探测功能,==将有价值的字节码编译成为本地机器指令==,以换取更高效的程序执行效率。
热点探测
热点代码
一个被多次调用的方法,或者是一个方法体内部循环次数较多的循环体都可以被称为热点代码
热点探测功能
检测热点代码。目前HotSpotJVM采用的是基于计数器的热点探测。HotSpot会为每个方法设立两个计数器:
- 方法调用计数器:统计方法调用次数
- 回边计数器:统计循环体执行的循环次数
方法调用计数器
统计方法调用的次数。默认阈值时Client模式下1500次,在Server模式下是10000次。超过这个阈值就会触发JIT编译。这个阈值可以通过-XX:CompileThreshold设定
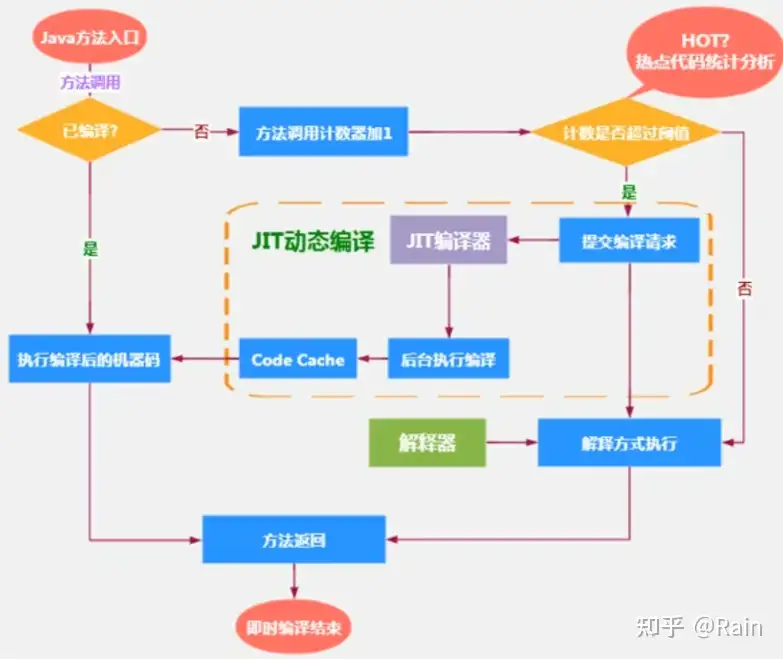
同时,该计数器统计方法调用次数并不是绝对值,而是一个相对的执行频率,即一段时间内方法的调用次数。当超过一定时间,该方法的调用次数还未达到阈值,则该方法的次数就会被减半,该过程称为调用方法计数器的热度衰减。而这段时间就被称为此方法的半衰周期
HotSpot中JIT编译器的分类
HotSpot中有两种编译器,分别是Client Compiler和Server Compiler,又称为C1和C2可以通过-client和-server使用哪一种
- Client Compiler:C1编译器会对字节码进行简单和可靠的优化,耗时短。以达到更快的编译速度。
- Server Compiler:C2进行较长时间的优化,以及激进优化,但优化的代码执行效率更高。
JDK7以后可以用-server命令开启分层编译策略,由C1、C2共同执行编译任务。
本地方法接口和本地方法库
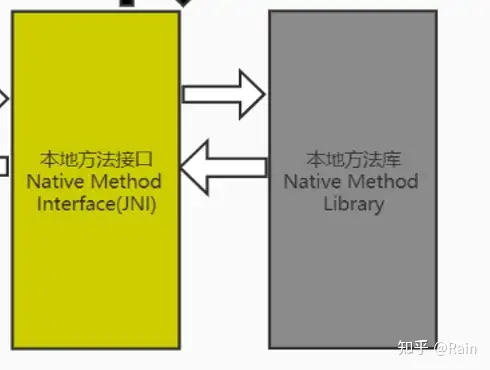
本地方法接口
JavaAPI库中有许多本地方法接口,例如:

这些被native修饰的方法就是本地方法接口,它们是通过C或者C++语言实现,并不是根据Java代码实现。
本地方法库
所谓本地方法库就是所有的本地方法组成的API库。
这里就是深入理解Java虚拟机第一章的全部内容,这里我们从类加载->运行时数据区->执行引擎->本地方法接口和本地方法库的流程完整的解释了JVM的总体架构。看完内容可以再回到文章开头参考文章开头的一张图,看图再回顾一下
本站推荐
-
1950
-
1838
-
1715
-
1203
-
1190