1)引入案例
#创建新表 createtabletest03 ( a1int(4)notnull, a2int(4)notnull, a3int(4)notnull, a4int(4)notnull ); #创建一个复合索引 createindexa1_a2_a3_test03ontest03(a1,a2,a3); #查看执行计划 explainselecta3fromtest03wherea1=1anda2=2anda3=3;
结果如下:
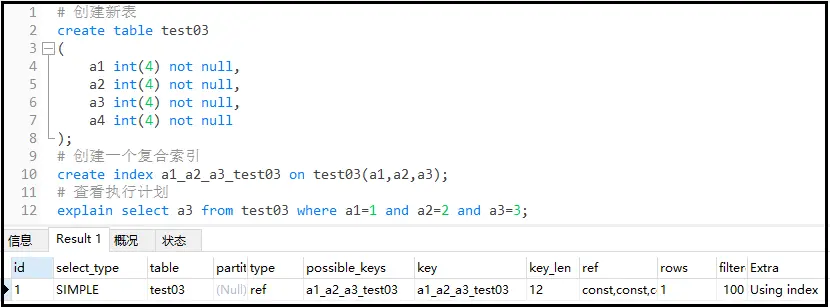
推荐写法:复合索引顺序和使用顺序一致。
下面看看【不推荐写法】:复合索引顺序和使用顺序不一致。
#查看执行计划 explainselecta3fromtest03wherea3=1anda2=2anda1=3;
结果如下:

结果分析:虽然结果和上述结果一致,但是不推荐这样写。但是这样写怎么又没有问题呢?这是由于SQL优化器的功劳,它帮我们调整了顺序。
最后再补充一点:对于复合索引,不要跨列使用
#查看执行计划 explainselecta3fromtest03wherea1=1anda3=2groupbya3;
结果如下:

结果分析:a1_a2_a3是一个复合索引,我们使用a1索引后,直接跨列使用了a3,直接跳过索引a2,因此索引a3失效了,当使用a3进行分组的时候,就会出现using where。
2)单表优化
#创建新表 createtablebook ( bidint(4)primarykey, namevarchar(20)notnull, authoridint(4)notnull, publicidint(4)notnull, typeidint(4)notnull ); #插入数据 insertintobookvalues(1,'tjava',1,1,2); insertintobookvalues(2,'tc',2,1,2); insertintobookvalues(3,'wx',3,2,1); insertintobookvalues(4,'math',4,2,3);
结果如下:
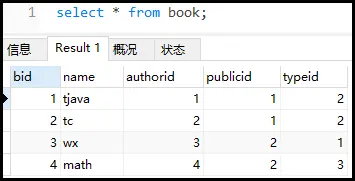
案例:查询authorid=1且typeid为2或3的bid,并根据typeid降序排列。
explain selectbidfrombook wheretypeidin(2,3)andauthorid=1 orderbytypeiddesc;
结果如下:
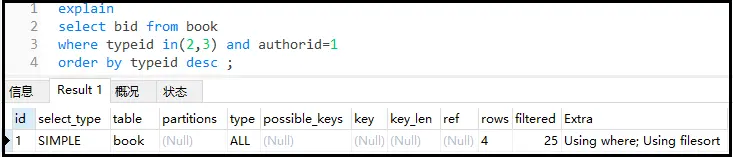
这是没有进行任何优化的SQL,可以看到typ为ALL类型,extra为using filesort,可以想象这个SQL有多恐怖。
优化:添加索引的时候,要根据MySQL解析顺序添加索引,又回到了MySQL的解析顺序,下面我们再来看看MySQL的解析顺序。
from..on..join..where..groupby..having..selectdinstinct..orderby..limit..
① 优化1:基于此,我们进行索引的添加,并再次查看执行计划。
#添加索引 createindextypeid_authorid_bidonbook(typeid,authorid,bid); #再次查看执行计划 explain selectbidfrombook wheretypeidin(2,3)andauthorid=1 orderbytypeiddesc;
结果如下:
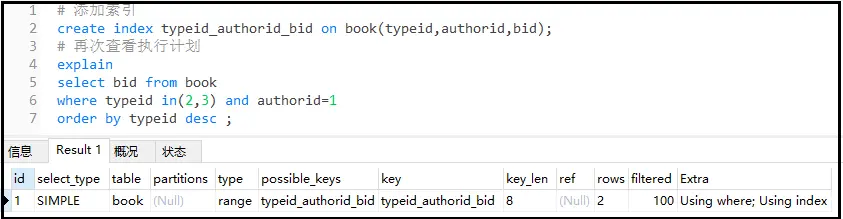
结果分析:结果并不是和我们想象的一样,还是出现了using where,查看索引长度key_len=8,表示我们只使用了2个索引,有一个索引失效了。
② 优化2:使用了in有时候会导致索引失效,基于此有了如下一种优化思路。
将in字段放在最后面。需要注意一点:每次创建新的索引的时候,最好是删除以前的废弃索引,否则有时候会产生干扰(索引之间)。
#删除以前的索引 dropindextypeid_authorid_bidonbook; #再次创建索引 createindexauthorid_typeid_bidonbook(authorid,typeid,bid); #再次查看执行计划 explain selectbidfrombook whereauthorid=1andtypeidin(2,3) orderbytypeiddesc;
结果如下:

结果分析:这里虽然没有变化,但是这是一种优化思路。
总结如下:
a.最佳做前缀,保持索引的定义和使用的顺序一致性
b.索引需要逐步优化(每次创建新索引,根据情况需要删除以前的废弃索引)
c.将含In的范围查询,放到where条件的最后,防止失效。
本例中同时出现了Using where(需要回原表); Using index(不需要回原表):原因,where authorid=1 and typeid in(2,3)中authorid在索引(authorid,typeid,bid)中,因此不需要回原表(直接在索引表中能查到);而typeid虽然也在索引(authorid,typeid,bid)中,但是含in的范围查询已经使该typeid索引失效,因此相当于没有typeid这个索引,所以需要回原表(using where);
例如以下没有了In,则不会出现using where:
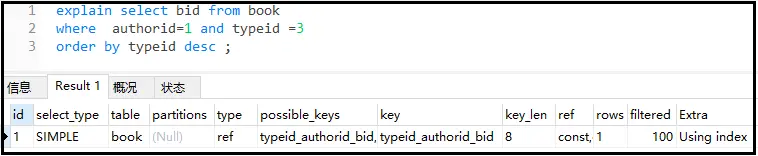
explainselectbidfrombook whereauthorid=1andtypeid=3 orderbytypeiddesc;
结果如下:
3)两表优化
#创建teacher2新表 createtableteacher2 ( tidint(4)primarykey, cidint(4)notnull ); #插入数据 insertintoteacher2values(1,2); insertintoteacher2values(2,1); insertintoteacher2values(3,3); #创建course2新表 createtablecourse2 ( cidint(4), cnamevarchar(20) ); #插入数据 insertintocourse2values(1,'java'); insertintocourse2values(2,'python'); insertintocourse2values(3,'kotlin');
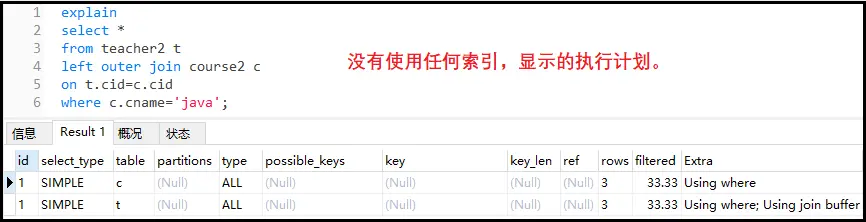
案例:使用一个左连接,查找教java课程的所有信息。
explain select* fromteacher2t leftouterjoincourse2c ont.cid=c.cid wherec.cname='java';
结果如下:
① 优化
对于两张表,索引往哪里加?答:对于表连接,小表驱动大表。索引建立在经常使用的字段上。
为什么小表驱动大表好一些呢?
小表:10 大表:300 #小表驱动大表 select...where小表.x10=大表.x300; for(inti=0;i<小表.length10;i++) { for(intj=0;j<大表.length300;j++) { ... } } #大表驱动小表 select...where大表.x300=小表.x10; for(inti=0;i<大表.length300;i++) { for(intj=0;j<小表.length10;j++) { ... } }
分析:以上2个FOR循环,最终都会循环3000次;但是对于双层循环来说:一般建议,将数据小的循环,放外层。数据大的循环,放内层。不用管这是为什么,这是编程语言的一个原则,对于双重循环,外层循环少,内存循环大,程序的性能越高。
结论:当编写【…on t.cid=c.cid】时,将数据量小的表放左边(假设此时t表数据量小,c表数据量大。)
我们已经知道了,对于两表连接,需要利用小表驱动大表,例如【…on t.cid=c.cid】,t如果是小表(10条),c如果是大表(300条),那么t每循环1次,就需要循环300次,即t表的t.cid字段属于,经常使用的字段,因此需要给cid字段添加索引。
更深入的说明:一般情况下,左连接给左表加索引。右连接给右表加索引。其他表需不需要加索引,我们逐步尝试。
#给左表的字段加索引 createindexcid_teacher2onteacher2(cid); #查看执行计划 explain select* fromteacher2t leftouterjoincourse2c ont.cid=c.cid wherec.cname='java';
结果如下:

当然你可以下去接着优化,给cname添加一个索引。索引优化是一个逐步的过程,需要一点点尝试。
#给cname的字段加索引 createindexcname_course2oncourse2(cname); #查看执行计划 explain selectt.cid,c.cname fromteacher2t leftouterjoincourse2c ont.cid=c.cid wherec.cname='java';
结果如下:

最后补充一个:Using join buffer是extra中的一个选项,表示Mysql引擎使用了“连接缓存”,即MySQL底层动了你的SQL,你写的太差了。
4)三表优化
大于等于张表,优化原则一样
小表驱动大表
索引建立在经常查询的字段上
本站推荐
-
1716
-
1617
-
1611
-
1552
-
1513